스파이더차트 그리기
개요
이번 글에서는 여러 변수의 특성을 비교할 때 유용한 스파이더차트(Spider chart) 또는 레이더차트(Radar chart)를 ggplot2를 사용해 직접 그리는 방법을 소개합니다. 이 차트는 데이터를 중심에서 뻗어나가는 축에 배치하여 각 그룹의 상대적 강점과 약점을 한눈에 파악할 수 있도록 도와줍니다.
2023년 기준 시도별 인구 특성을 나타내는 실제 데이터를 사용하며, 데이터를 처리하고 좌표를 계산하여 스파이더차트를 구현하는 전 과정을 다룹니다. 이번 글은 How to Make a Spider Chart in R Using ggplot2을 참고해 작성되었으며, 더 이해하기 쉽고 실용적으로 수정된 코드를 제공합니다.
다만, 이 글에서는 삼각함수를 활용해 각도를 계산하고, 데이터를 변환해 좌표를 직접 지정하는 과정을 상세히 다루기 때문에, 복잡하게 느껴질 수 있습니다. 하지만 과정을 하나씩 따라가며 이해하면, 스파이더차트를 활용한 데이터 시각화의 강력한 가능성을 느낄 수 있을 것입니다.
데이터 준비하기
시도별 청년인구 비율, 고령인구 비율, 전입/전출 비율, 출생아 비율, 사망자 비율을 계산한 데이터를 사용하려고 합니다. 아래 원자료를 가공해 각 변수를 구하고 스파이더차트를 그릴 준비를 합니다.
| 데이터 | 출처 |
|---|---|
| 청년인구, 고령인구 수 | 행정구역(읍면동)별/5세별 주민등록인구(2011년~) |
| 전입인구 수 | 전입인구(시도/시/군/구) |
| 전출인구 수 | 전출인구(시도/시/군/구) |
| 출생아 수 | 출생아수(시도/시/군/구) |
| 사망자 수 | 사망자수(시도/시/군/구) |
# 패키지 로드
library(tidyverse)
library(readxl)
library(ggplot2)
library(showtext)
library(scales)
# 글꼴 설정
font_add("kopub", "C:/Users/.../AppData/Local/Microsoft/Windows/Fonts/KoPub Dotum Medium.ttf")
showtext_auto()
showtext_opts(dpi=300)
theme.size = 12
text.size = theme.size / .pt
# 데이터 불러오기
pop <- read_xlsx("데이터/시도 인구 특성/5세별주민등록인구_시도_2023.xlsx")
in_pop <- read_xlsx("데이터/시도 인구 특성/전입인구_시도_2023.xlsx")
out_pop <- read_xlsx("데이터/시도 인구 특성/전출인구_시도_2023.xlsx")
births <- read_xlsx("데이터/시도 인구 특성/출생아수_시도_2023.xlsx", skip=1)
deaths <- read_xlsx("데이터/시도 인구 특성/사망자수_시도_2023.xlsx")
5세별 주민등록인구 데이터를 가공하여 시도별 전체 인구 수, 청년인구 수, 고령인구 수를 계산합니다. 청년인구는 만 20~34세, 고령인구는 만 65세 이상으로 정의했습니다. 출생아 수와 사망자 수를 나타낸 데이터의 일부 지역명을 수정하여 데이터 간 지역명을 일치시켜줍니다. 모든 데이터를 하나로 통합한 후 비율을 계산하고 데이터를 정리하여 완성합니다.
# 연령 정의
age <- unique(pop$`5세별`)
youth <- age[5:6]
senior <- age[-(1:13)]
# 시도 순서
sido_order <- unique(pop$`행정구역(동읍면)별`)[-1]
# 5세별 주민등록인구 데이터 정리하기
pop_sum <- pop %>%
rename(시도 = `행정구역(동읍면)별`) %>%
mutate(구분 = case_when(`5세별` %in% youth ~ "청년인구 수",
`5세별` %in% senior ~ "고령인구 수",
T ~ "그 외 인구 수")) %>%
group_by(시도, 구분) %>%
summarise(`인구 수` = sum(`2023`, na.rm = T)) %>%
pivot_wider(id_cols = 시도, names_from = 구분, values_from = `인구 수`) %>%
mutate(`인구 수` = `청년인구 수` + `고령인구 수` + `그 외 인구 수`) %>%
select(-`그 외 인구 수`) %>%
filter(시도 != "전국")
# 시군구 명칭 통일시키기
births <- births %>%
mutate(시군구별 = case_when(시군구별 == "전라북도" ~ "전북특별자치도",
T ~ 시군구별))
deaths <- deaths %>%
mutate(시군구별 = case_when(시군구별 == "강원도" ~ "강원특별자치도",
시군구별 == "전라북도" ~ "전북특별자치도",
시군구별 == "제주도" ~ "제주특별자치도",
T ~ 시군구별))
# 비율 계산하기
data <- pop_sum %>%
left_join(in_pop, by=c("시도"="행정구역(시군구)별(1)")) %>%
select(-`성별(1)`) %>%
rename(`전입인구 수` = `2023`) %>%
left_join(out_pop, by=c("시도"="행정구역(시군구)별(1)")) %>%
select(-`성별(1)`) %>%
rename(`전출인구 수` = `2023`) %>%
left_join(births, by=c("시도"="시군구별")) %>%
rename(`출생아 수` = `계 (명)`) %>%
left_join(deaths, by=c("시도"="시군구별")) %>%
select(-성별) %>%
rename(`사망자 수` = `2023`) %>%
mutate(`고령인구 비율` = `고령인구 수`/`인구 수`,
`청년인구 비율` = `청년인구 수`/`인구 수`,
`전입인구 비율` = `전입인구 수`/`인구 수`,
`전출인구 비율` = `전출인구 수`/`인구 수`,
`출생아 비율` = `출생아 수`/`인구 수`,
`사망자 비율` = `사망자 수`/`인구 수`,
시도 = factor(시도, levels = sido_order)) %>%
select(시도, contains("비율"))
# 데이터 확인하기
head(data)
## # A tibble: 6 × 7
## # Groups: 시도 [6]
## 시도 `고령인구 비율` `청년인구 비율` `전입인구 비율` `전출인구 비율`
## <fct> <dbl> <dbl> <dbl> <dbl>
## 1 강원특별자치도 0.240 0.107 0.113 0.114
## 2 경기도 0.156 0.123 0.123 0.120
## 3 경상남도 0.206 0.0993 0.0924 0.0974
## 4 경상북도 0.247 0.0972 0.0996 0.103
## 5 광주광역시 0.165 0.135 0.115 0.121
## 6 대구광역시 0.196 0.119 0.125 0.127
## # ℹ 2 more variables: `출생아 비율` <dbl>, `사망자 비율` <dbl>
스파이더차트의 기본 원리
ggradar 함수를 이용하면 스파이더차트를 간편하게 그릴 수 있습니다. 하지만, 차트의 세부요소를 조정하기 쉽지 않다는 단점이 있습니다. 이보다 복잡하지만 ggplot2를 이용해 직접 차트를 그리면 세부요소를 마음대로 조정할 수 있어서 이번 시간에는 ggplot2를 이용하는 방법을 알려드리겠습니다.
스파이더차트에서 각 변수는 중심에서 뻗어나가는 축을 따라 배치됩니다. 점의 위치는 반지름(r)과 각도(θ)를 기반으로 계산할 수 있습니다. 점의 좌표를 구하는 공식은 x = r·cos(θ), y = r·sin(θ)이며, 원리는 아래 도표와 같습니다.
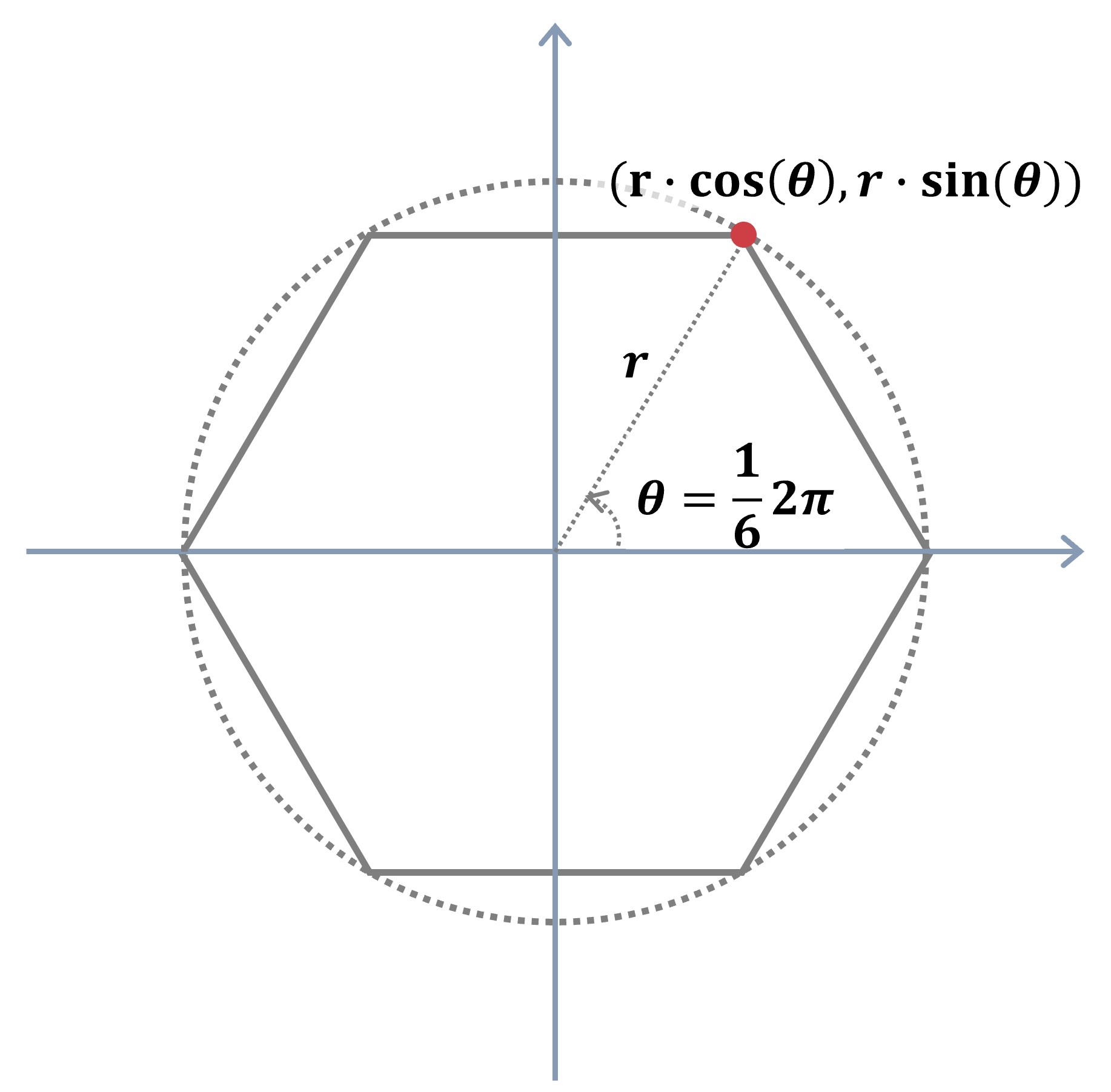
스파이더차트를 그리기 위해서는 각 변수의 값이 동일한 범위(예: 0~100%)로 변환되어야 합니다. 사실 이번 예제에서 사용할 데이터는 모두 비율 데이터로 0~100% 사이의 값을 지녀, 값을 변환할 필요가 없습니다. 하지만, 고령인구 비율이 11.0~26.1% 사이의 값인 반면 출생아 비율은 0.4~0.7% 사이의 값을 지니기 때문에 축의 범위를 0~100%로 동일하게 설정했을 때 지역 간 출생아 비율 차이를 파악하기 쉽지 않습니다. 따라서, 최소값은 차트의 r = 0.2에 대응하고 최대값은 r = 1에 대응하도록 아래 수식을 이용하여 변수별로 범위를 조정할 필요가 있습니다.
scaled = (x - xmin)/(xmax - xmin)·(1 - 0.2) + 0.2
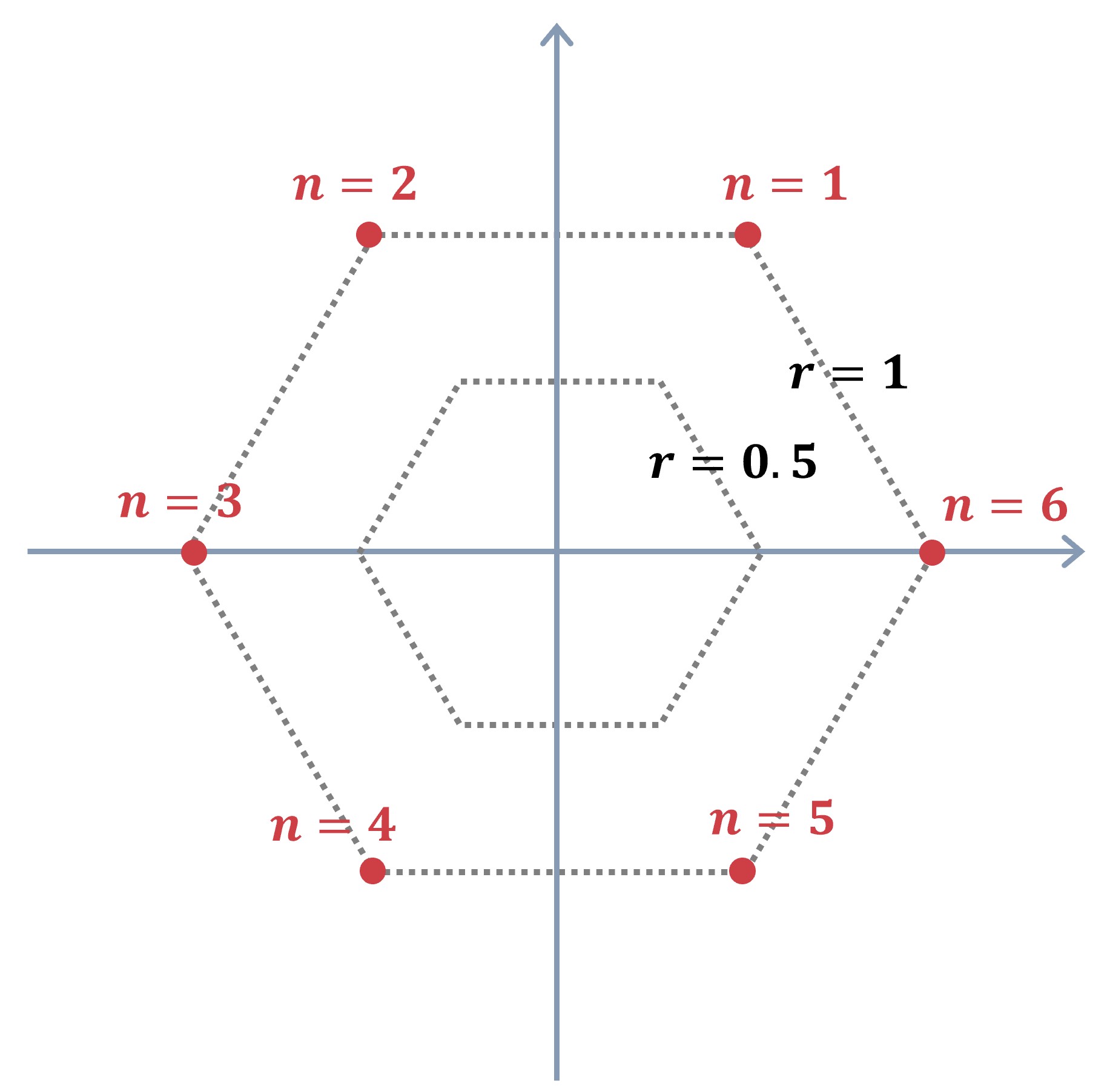
이렇게 변환된 값을 기준으로 각 변수의 좌표를 계산합니다. 원의 한 바퀴는 360도이며 이를 라디안으로 표현하면 2π입니다. 만약 n개의 변수가 있다면, 변수 하나가 차지하는 각도는 2π/n이 됩니다. 이를 코드로 구현하면 seq(0, 2 * pi, length.out = n + 1)이 됩니다. n + 1을 하는 이유는 원의 시작점(theta)에서 다시 원의 시작점(2 * pi)까지 총 n + 1개 요소를 뽑기 때문입니다. 원의 시작점이 요소에 포함되기 때문에 n + 1개 요소를 뽑도록 지정해 주어야 합니다. 아래 그림은 n=6일 때, 스파이더차트가 어떻게 구성되는지를 보여줍니다. r과 n의 조합으로 각 점의 특정할 수 있습니다.
스파이더차트의 배경 그리기
- 차트에서 표현할 변수의 축 개수를 구합니다.
- 변수명을 추출하고 변수의 순서를 지정합니다.
- 차트의 중심이 0이고 축의 길이를 1로 가정하며, 그리드 간격을
0.2로 설정합니다. - 각 변수의 최소값과 최대값이 0.2와 1에 대응하도록 변환하는 함수(
scaling)를 정의합니다. - 반지름(
r)과 변수 개수(n_axis)를 입력하면, 특정 반지름에 해당하는 점 좌표를 변수 개수만큼 생성하는 함수(gen_coords)를 정의합니다. - 변수 벡터(
x), 그리드 간격(offset)를 입력하면, 해당 변수를 축에 표현할 때 그리드가 그려지는 지점의 실제값과 해당 위치의 반지름(r)을 반환하는 함수(axis_text)를 정의합니다.
# 변수 개수
n_axis <- ncol(data) - 1
# 변수 순서
vars_nth <- tibble(구분 = colnames(data)[-1],
n = 1:n_axis)
# 그리드 간격
offset <- 0.2
# 데이터 스케일링 함수(최소값이 0.2, 최대값이 1에 대응하도록 스케일링하는 함수)
scaling <- function(x, min_val = offset, max_val = 1){
x_min <- min(x, na.rm = T)
x_max <- max(x, na.rm = T)
scaled <- (x - x_min) / (x_max - x_min) * (max_val - min_val) + min_val
return(scaled)
}
# 데이터 좌표 계산하는 함수 정의
gen_coords <- function(r, n_axis, closed = FALSE){
angles <- seq(0, 2 * pi, length.out = n_axis + 1) + pi / 2
if(closed==FALSE){
angles <- angles[-length(angles)]
}
x <- r * cos(angles)
y <- r * sin(angles)
n <- 1:length(angles)
tibble(x, y, r, n)
}
# 변수별 축 텍스트 함수
axis_text <- function(x, offset){
min <- min(x, na.rm = T)
max <- max(x, na.rm = T)
label <- seq(min, max, length.out = 1 / offset)
r <- seq(offset, 1, by = offset) # 최소값이 차트 반지름 0.2에 대응, 최대값이 차트 반지름 1에 대응
tibble(label, r)
}
스파이더차트의 배경은 외곽배경, 그리드선, 축선, 축선에 표시될 축 타이틀과 텍스트로 구성됩니다. 아래 코드는 스파이더차트의 외곽배경, 그리드선, 축선을 만드는 과정을 보여줍니다. panel_data는 스파이더차트를 구성하는 배경 점 좌표를 계산하여 저장한 데이터프레임입니다. seq(0, 1, by = offset)[-1]은 차트의 중심에서 외곽까지의 반지름 값을 나타내고, 각 반지름 값에 대해 gen_coords 함수를 호출하여 점 좌표를 계산합니다. 함수의 결과는 모든 반지름 값에 대한 좌표를 하나의 데이터프레임으로 결합한 형태가 됩니다.
# 배경 점 좌표
panel_data <- map_df(
seq(0, 1, by = offset)[-1],
~gen_coords(.x, n_axis, closed=T)
)
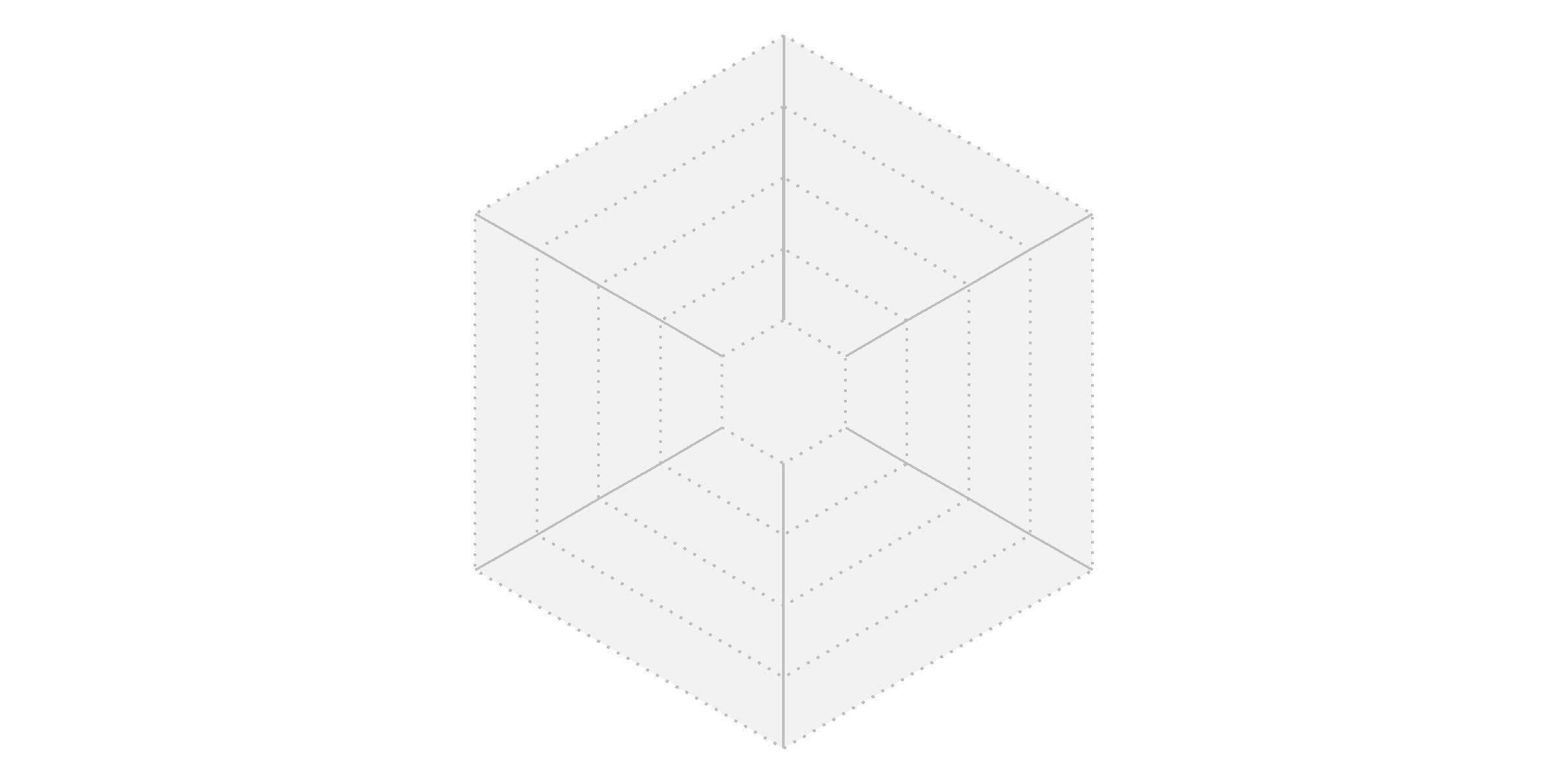
panel_bg는 생성된 배경 좌표 데이터를 이용해 차트를 그린 결과물입니다. geom_polygon을 사용해 반지름 값이 1인 외곽선으로 구성된 폴리곤을 회색으로 채우고, 투명도를 조절해 배경의 기본 윤곽을 만듭니다. geom_path를 통해 각 반지름 값을 따라 점선을 그려 그리드를 완성합니다. 마지막으로 geom_line을 이용해 중심에서 각 축 끝까지 선을 그려 변수를 표현할 축을 추가합니다. 불필요한 시각적 요소는 theme_void를 통해 제거하여 차트를 깔끔하게 정리합니다.
# 배경 그리기
panel_bg <- ggplot() +
# 외곽 배경(r = 1)
geom_polygon(data = panel_data %>% filter(r == 1),
aes(x, y),
fill = "gray",
alpha = 0.2) +
# 점선 그리드
geom_path(data = panel_data,
aes(x, y, group = r),
linetype = "dotted",
color = "gray") +
# 축 추가
geom_line(data = panel_data,
aes(x = x, y = y, group = n),
color = "gray") +
coord_fixed(ratio = 1,
clip = "off") +
theme_void()
panel_bg
다음으로, 축에 변수명과 텍스트를 추가하겠습니다. axis_text_data는 각 축에 표시될 값인 축 텍스트를 계산한 결과를 담고 있습니다. pivot_longer 함수를 이용해 데이터를 길게 변환하고, axis_text 함수를 호출해 각 변수별로 축 텍스트에 해당하는 값과 반지름을 계산합니다. 그리고, vars_nth와 panel_data 데이터를 결합하여 변수의 순서와 텍스트를 배치할 좌표를 구합니다.
# 축 텍스트 데이터
axis_text_data <- data %>%
pivot_longer(cols = -시도, names_to = "구분", values_to = "실제값") %>%
group_by(구분) %>%
# 변수별 축 데이터 실제값 구하기
reframe(axis_text(실제값, offset)) %>%
# 변수 순서 지정하기
left_join(vars_nth, by = "구분") %>%
# 좌표 추가하기
left_join(panel_data, by = c("r", "n"))
# 데이터 확인하기
head(axis_text_data)
## # A tibble: 6 × 6
## 구분 label r n x y
## <chr> <dbl> <dbl> <int> <dbl> <dbl>
## 1 고령인구 비율 0.110 0.2 1 1.22e-17 0.2
## 2 고령인구 비율 0.148 0.4 1 2.45e-17 0.4
## 3 고령인구 비율 0.186 0.6 1 3.67e-17 0.6
## 4 고령인구 비율 0.223 0.8 1 4.90e-17 0.8
## 5 고령인구 비율 0.261 1 1 6.12e-17 1
## 6 사망자 비율 0.00413 0.2 6 1.73e- 1 0.100
변수명을 축의 끝부분에 배치하기 위해 좌표를 새로 계산해야 합니다. gen_coords 함수를 이용하여, 반지름 1.15, 변수 6개에 대한 좌표를 계산하고 axis_title_coords에 저장합니다. 이후 변수명에 변수의 순서(vars_nth)와 좌표(axis_title_coords)를 결합하여 axis_title_data를 만듭니다.
# 축 타이틀 좌표
axis_title_coords <- gen_coords(1.15, 6)
# 축 타이틀 데이터
axis_title_data <- data %>%
pivot_longer(cols = -시도, names_to = "구분", values_to = "실제값") %>%
group_by(구분) %>%
summarise() %>%
# 변수 순서 지정하기
left_join(vars_nth, by = "구분") %>%
# 좌표 추가하기
left_join(axis_title_coords, by = c("n")) %>%
mutate(hjust = case_when(x > 0.01 ~ 0,
x < -0.01 ~ 1,
T ~ 0.5))
위 데이터를 활용하여 스파이더차트에 축 텍스트와 변수명을 추가해줍니다.
panel_bg_with_axis <- panel_bg +
# 축 텍스트 표기
geom_text(data = axis_text_data,
aes(x, y, label = percent(label, accuracy = .01, suffix = "")),
color = "gray30",
family = "kopub",
size = text.size * 0.8) +
# 축 변수명 표기
geom_text(data = axis_title_data,
aes(x, y, label = paste0(구분, "(%)")),
family = "kopub",
size = text.size,
hjust = axis_title_data*hjust)
panel_bg_with_axis
배경에 데이터 추가하기
각 데이터 포인트를 좌표로 변환하고 경로가 닫히도록 시도별 첫번째 행을 복사해서 행에 추가해 줍니다.
# 데이터 가공
tmp <- data %>%
pivot_longer(cols = -시도, names_to = "구분", values_to = "실제값") %>%
# 실제값을 스케일링하기
group_by(구분) %>%
mutate(변환값 = scaling(실제값)) %>%
# 변환값의 좌표 구하기
group_by(시도) %>%
mutate(coords = gen_coords(변환값, n_axis)) %>%
unnest(cols = c(coords)) %>%
# 부산, 울산, 경남만 추출하기
filter(시도 %in% c("부산광역시", "울산광역시", "경상남도"))
# geom_path 사용 시 닫힌 경로 만들기 위해 시도별 첫번째 행 복사하기
tmp_first_row <- tmp %>%
group_by(시도) %>%
filter(row_number() == 1)
final_data <- tmp %>%
bind_rows(tmp_first_row)
이제 마지막입니다! 스파이더차트 배경 위에 데이터를 표현하여 차트를 완성합니다. geom_path와 geom_point 함수를 이용하여 데이터 라인과 포인트를 추가합니다. geom_path는 각 시도의 데이터를 연결하여 라인을 그리는 역할을 하고, geom_point는 라인 위에 데이터 포인트를 표시하는 역할을 합니다.
데이터 라인과 포인트 색상은 scale_color_brewer(palette = "Set2")로 설정했으며, RColorBrewer 팔레트의 “Set2” 색상 세트를 적용했습니다. theme을 사용하여 범례 제목을 없애고 범례 위치와 범례 항목의 사이즈를 조정해 주었습니다.
panel_bg_with_axis +
# 데이터 라인 그리기
geom_path(data = final_data,
aes(x, y, group = 시도 , color = 시도),
linewidth = 1) +
# 데이터 포인트 그리기
geom_point(data = final_data,
aes(x, y, group = 시도, color = 시도),
size = 3,
shape = 21,
fill = "white") +
scale_color_brewer(palette = "Set2") +
theme(
legend.position = "bottom",
legend.title = element_blank(),
legend.key.height = unit(theme.size, "pt"),
legend.margin = margin(5, 0, 0, 0),
legend.background = element_rect(fill = NA, color = NA)
)
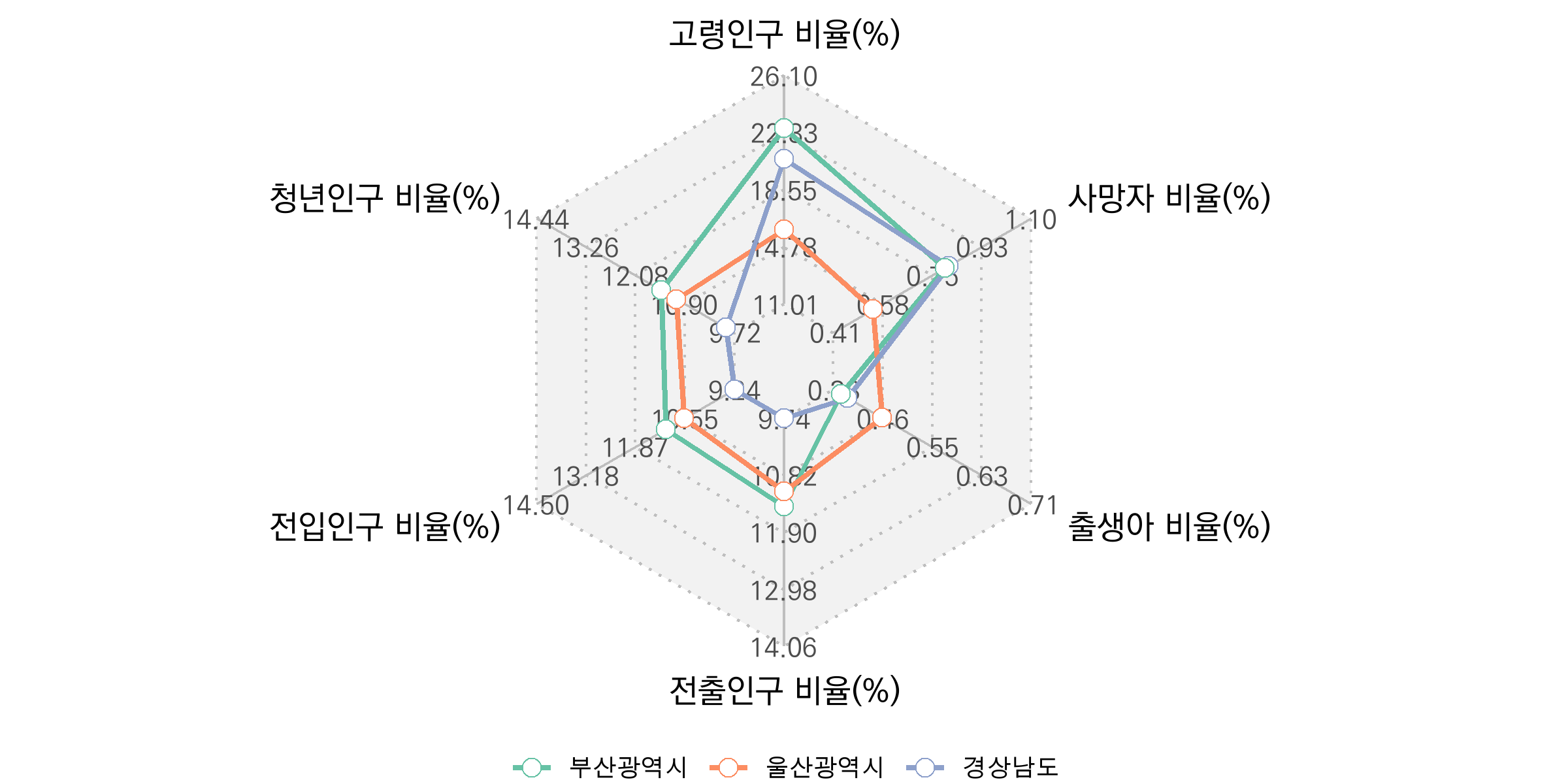
스파이더차트는 다차원 데이터를 한눈에 비교하고 시각화할 수 있는 강력한 도구입니다. 이번 글에서는 데이터를 변환하고 좌표를 계산하여 ggplot2를 사용해 스파이더차트를 그리는 방법을 알아보았습니다. 스파이더차트를 제작하는 과정은 처음에는 복잡하게 느껴질 수 있지만, 데이터의 상대적인 패턴과 차이를 시각적으로 명확히 표현할 수 있으니 한 번 활용해 보세요!