교차 지점의 텍스트 중첩 문제 해결하기
개요
선 그래프를 시각화할 때, 두 선이 교차하는 지점에서 텍스트가 겹치는 문제가 종종 발생합니다. 이런 경우, 더 높은 값의 텍스트는 위로, 더 낮은 값의 텍스트는 아래로 위치를 조정하여 가독성을 높일 수 있습니다. 이번 글에서는 서울과 경기의 주민등록인구 데이터를 활용해 선 그래프 텍스트 겹침 문제를 해결하는 방법을 소개하겠습니다.
데이터 준비하기
먼저, 필요한 패키지를 로드하고 차트에 사용할 글꼴을 설정합니다.
# 패키지 로드
library(readxl)
library(tidyverse)
library(ggplot2)
library(showtext)
library(scales)
# 차트 글꼴 설정
font_add("kopub", "C:/Users/.../AppData/Local/Microsoft/Windows/Fonts/KoPub Dotum Medium.ttf")
showtext_auto()
showtext_opts(dpi=300)
theme.size = 12
text.size = theme.size / .pt
1995년부터 2023년까지의 시도별 주민등록인구 데이터를 로드한 후 데이터를 가공합니다. 주민등록인구 수는 만 명 단위로 변환하며, 서울과 경기에 해당하는 데이터만 추출합니다.
# 데이터 로드
data <- read_xlsx("데이터/주민등록인구_시도_1995-2023.xlsx")
# 데이터 가공
data <- data %>%
rename(시도 = 행정구역별,
주민등록인구수 = `계 (명)`) %>%
filter(시도 %in% c("서울특별시", "경기도")) %>%
mutate(시점 = as.character(시점),
주민등록인구수 = as.numeric(주민등록인구수) / 10000,
시도 = factor(시도, levels = c("서울특별시", "경기도")))
# 데이터 확인
head(data)
## # A tibble: 6 × 3
## 시도 시점 주민등록인구수
## <fct> <chr> <dbl>
## 1 서울특별시 1995 1055.
## 2 서울특별시 1996 1042.
## 3 서울특별시 1997 1034.
## 4 서울특별시 1998 1027.
## 5 서울특별시 1999 1026.
## 6 서울특별시 2000 1031.
선그래프 그리기
1995년부터 2023년까지 서울과 경기의 주민등록인구 변화를 선 그래프로 시각화합니다. 데이터 포인트를 강조하기 위해 geom_point를 추가하고, 주민등록인구 값을 텍스트로 표기합니다. 그래프를 보면, 특정 시점에서 두 선이 교차하며 텍스트가 겹치는 문제가 발생합니다.
data %>%
ggplot(aes(x = 시점, y = 주민등록인구수,
group = 시도, color = 시도,
label = comma(주민등록인구수, accuracy = 1))) +
geom_line(linewidth = 0.4) +
geom_point(size = 3) +
geom_text(vjust = -1,
family = "kopub",
size = text.size,
color = "gray10") +
scale_x_discrete(name = "") +
scale_y_continuous(name = "주민등록인구 수(만 명)",
expand = expansion(mult = 0.2),
labels = comma_format()) +
theme_minimal(base_size = theme.size, base_family = "kopub") +
theme(
axis.line = element_line(linewidth = 0.5, color = "gray10"),
axis.ticks = element_line(linewidth = 0.1, color = "gray10"),
panel.grid.minor = element_blank(),
axis.text = element_text(color = "gray10"),
axis.text.x = element_text(angle = 45, vjust = 1, hjust = 1)
)
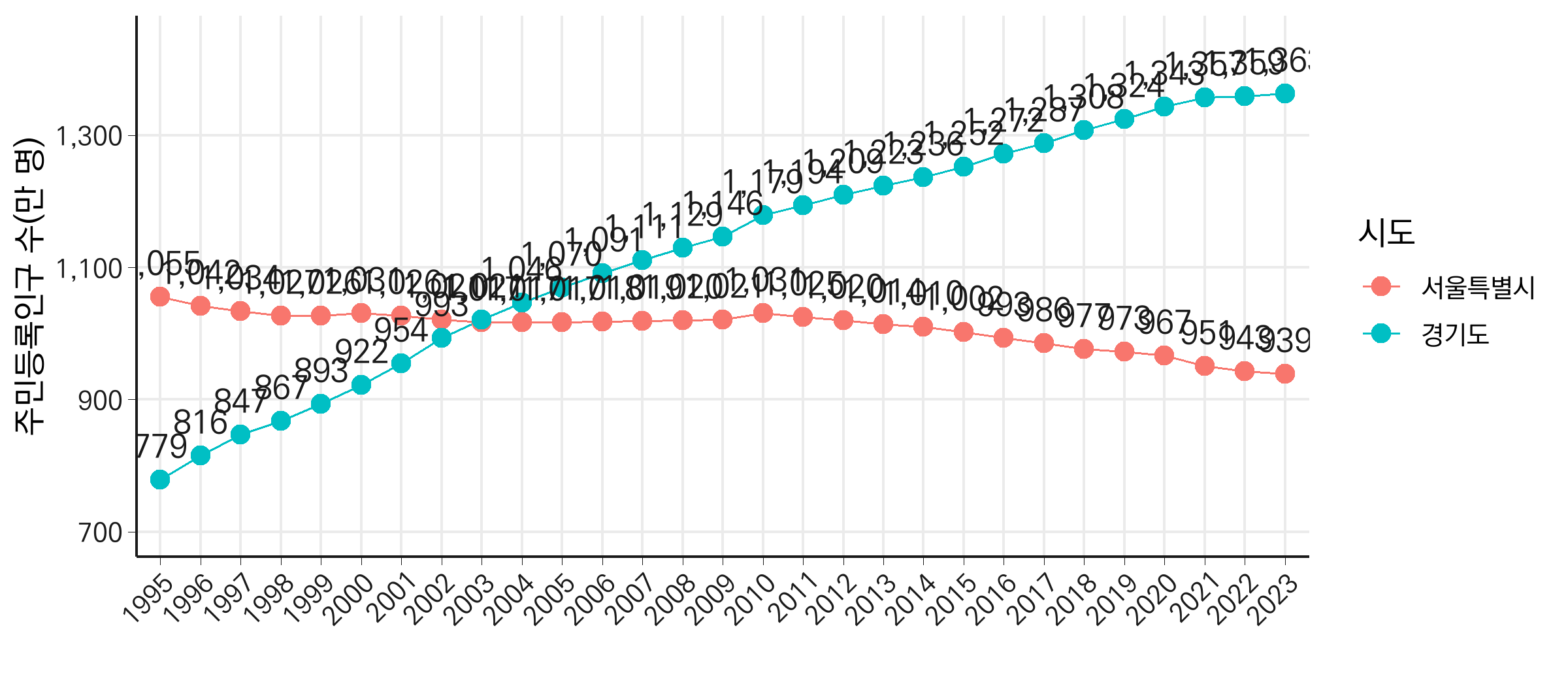
텍스트 위치 조정하기
두 텍스트가 겹치지 않도록 값을 비교해 텍스트의 위치를 조정합니다. 더 높은 값의 텍스트는 위쪽(vjust = -1), 더 낮은 값의 텍스트는 아래쪽(vjust = 1.5)으로 배치되도록 case_when을 사용해 vjust 값을 계산합니다. 이를 활용하여 geom_text의 vjust에 동적으로 적용합니다.
또한, 공간에 비해 텍스트가 많아 텍스트 위치를 조정해도 서로 겹치는 문제가 발생하므로, 2년 간격으로 텍스트를 표기하는 걸로 수정하겠습니다.
data2 <- data %>%
mutate(라벨 = case_when(시점 %in% as.character(seq(1995, 2023, by = 2)) ~ 주민등록인구수,
T ~ as.numeric(NA))) %>%
group_by(시점) %>%
mutate(vjust = case_when(주민등록인구수 == max(주민등록인구수) ~ -1,
T ~ 1.5))
data2 %>%
ggplot(aes(x = 시점, y = 주민등록인구수,
group = 시도, color = 시도,
label = comma(라벨, accuracy = 1))) +
geom_line(linewidth = 0.4) +
geom_point(size = 3) +
geom_text(vjust = data2$vjust,
family = "kopub",
size = text.size,
color = "gray10") +
scale_x_discrete(name = "",
expand = expansion(mult = 0.05)) +
scale_y_continuous(name = "주민등록인구 수(만 명)",
expand = expansion(mult = 0.2),
labels = comma_format()) +
scale_color_brewer(palette = "Dark2") +
theme_minimal(base_size = theme.size, base_family = "kopub") +
theme(
axis.line = element_line(linewidth = 0.5, color = "gray10"),
axis.ticks = element_line(linewidth = 0.1, color = "gray10"),
panel.grid.minor = element_blank(),
axis.text = element_text(color = "gray10"),
axis.text.x = element_text(angle = 45, vjust = 1, hjust = 1),
legend.title = element_blank(),
legend.position = "bottom"
)
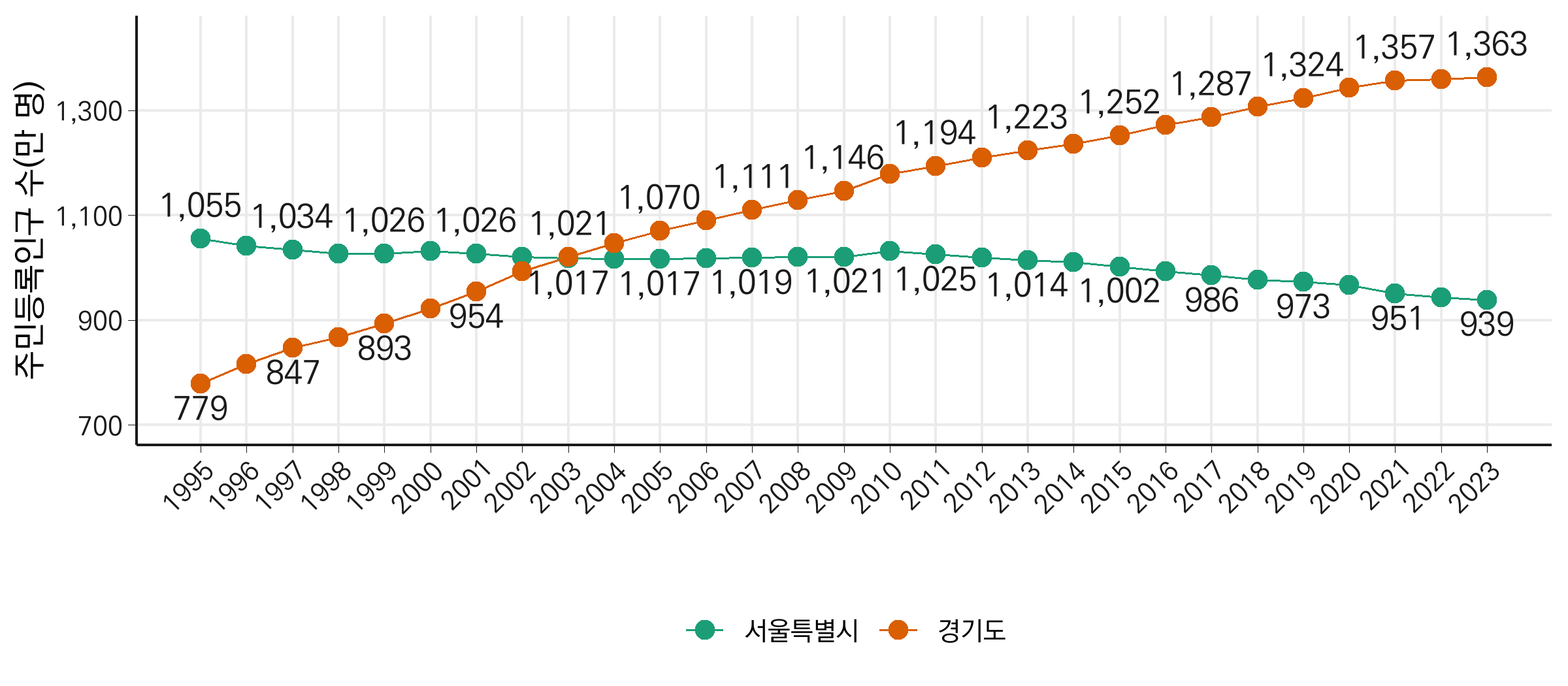
텍스트 위치를 동적으로 조정하는 이 방법은 선 그래프에서 발생할 수 있는 텍스트 겹침 문제를 깔끔하게 해결해줍니다. 특히, 두 값이 교차하거나 선이 가까운 상황에서도 그래프의 가독성을 유지할 수 있다는 장점이 있습니다. 다른 데이터셋에서도 비슷한 문제가 생긴다면, 이 방법을 활용해 보세요!