선 그래프 끝 지점에 텍스트 추가하기
개요
이번 글에서는 선 그래프에서 각 선이 어떤 그룹(시도)을 나타내는지 보다 직관적으로 표시하는 방법을 소개합니다. 일반적으로 선 그래프는 색상(color), 선 타입(linetype), 모양(shape) 등을 활용하여 그룹을 구분하고, 범례를 통해 그룹명을 표시합니다. 하지만 그룹 수가 많아질수록 범례만으로는 각각의 선이 무엇을 나타내는지 파악하기 어려워집니다. 이를 해결하기 위해, 선 그래프의 끝 지점에 각 그룹명을 텍스트로 표기하는 방법을 활용하면 해석이 훨씬 쉬워집니다.
이 글에서는 1995년부터 2023년까지의 시도별 주민등록인구 데이터를 선 그래프로 시각화하고, 선의 끝 부분에 해당하는 그룹명을 텍스트로 표기하여 보다 직관적으로 데이터를 표현하는 방법을 다룹니다.
데이터 준비하기
먼저, 필요한 패키지를 로드하고 차트에서 사용할 글꼴을 설정합니다. ggplot2를 활용해 선 그래프를 그릴 것이며, 텍스트가 겹치는 문제를 해결하기 위해 ggrepel 패키지를 사용합니다.
# 패키지 로드
library(readxl)
library(tidyverse)
library(ggplot2)
library(showtext)
library(scales)
library(lubridate)
library(ggrepel)
# 차트 글꼴 설정
font_add("kopub", "C:/Users/.../AppData/Local/Microsoft/Windows/Fonts/KoPub Dotum Medium.ttf")
showtext_auto()
showtext_opts(dpi=300)
theme.size = 12
text.size = theme.size / .pt
통계청에서 다운받은 1995~2023년 시도별 주민등록인구 데이터를 로드합니다. 칼럼명을 수정하고 전국 데이터를 제거하는 등 분석에 적합한 형태로 데이터를 가공합니다.
# 데이터 로드
data <- read_xlsx("데이터/주민등록인구_시도_1995-2023.xlsx")
# 데이터 가공
data <- data %>%
rename(시도 = 행정구역별,
주민등록인구수 = `계 (명)`) %>%
filter(시도 != "전국") %>%
mutate(시점 = as.character(시점),
주민등록인구수 = as.numeric(주민등록인구수))
# 데이터 확인
head(data)
## # A tibble: 6 × 3
## 시도 시점 주민등록인구수
## <chr> <chr> <dbl>
## 1 서울특별시 1995 10550871
## 2 서울특별시 1996 10418076
## 3 서울특별시 1997 10336134
## 4 서울특별시 1998 10270506
## 5 서울특별시 1999 10264260
## 6 서울특별시 2000 10311314
선그래프 그리기
1995년부터 2023년까지의 주민등록인구 변화를 선 그래프로 시각화합니다. 이를 위해, 데이터의 시점을 X축에, 주민등록인구수를 Y축에 매핑하고, 시도를 그룹화하여 선을 그립니다. 또한, 색상을 시도에 따라 다르게 지정해 각 선을 구분합니다. geom_line 함수로 선을 그린 뒤, geom_point를 추가하여 데이터 포인트를 강조합니다.
data %>%
ggplot(aes(x = 시점, y = 주민등록인구수,
group = 시도, color = 시도)) +
geom_line(linewidth = 0.4) +
geom_point(size = 3) +
scale_x_discrete(name = "") +
scale_y_continuous(name = "주민등록인구 수(명)",
expand = expansion(mult = c(0, 0.1))) +
theme_minimal(base_size = theme.size, base_family = "kopub") +
theme(
axis.line = element_line(linewidth = 0.5, color = "gray10"),
axis.ticks = element_line(linewidth = 0.1, color = "gray10"),
panel.grid.minor = element_blank(),
axis.text = element_text(color = "gray10")
)
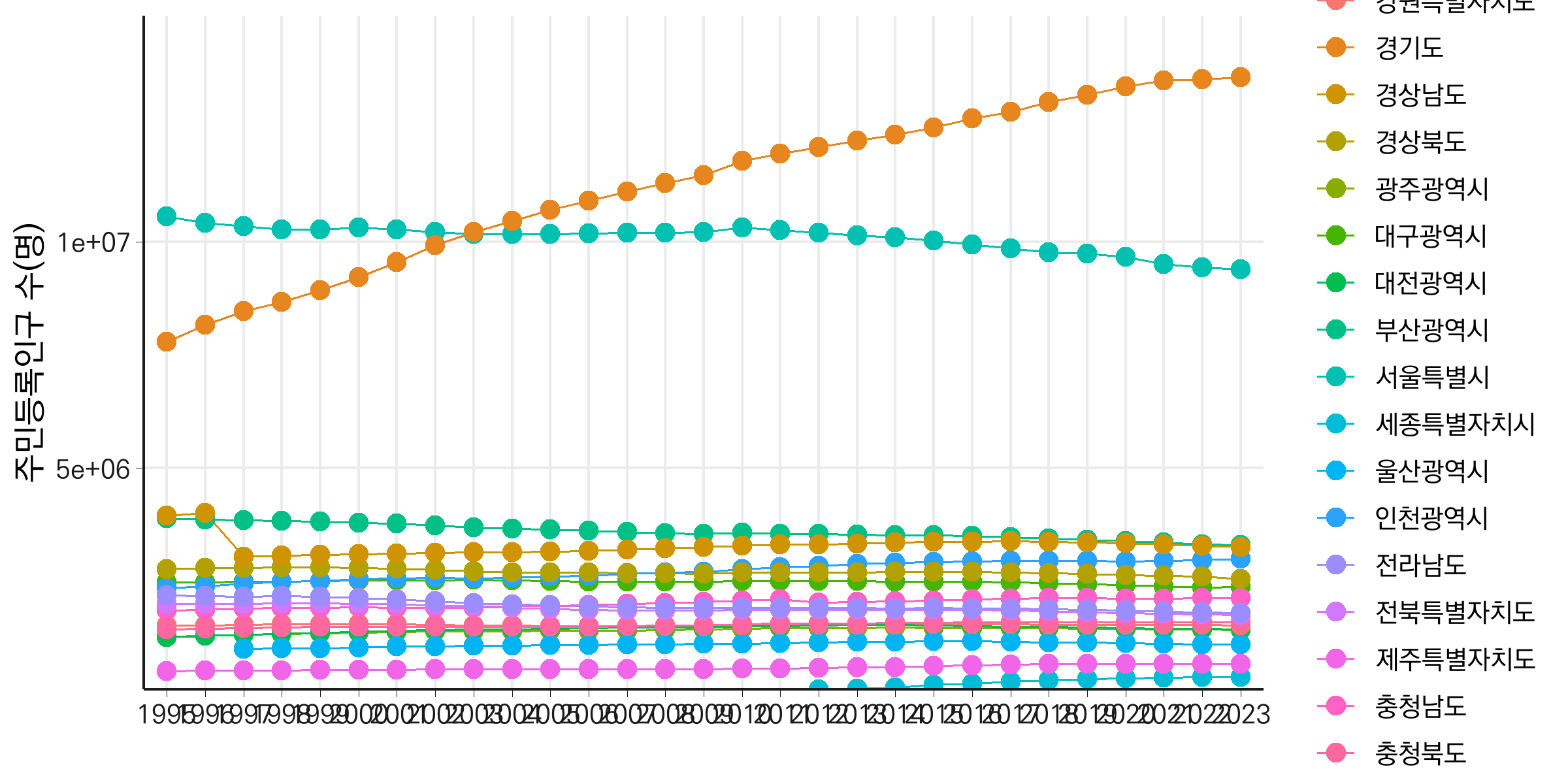
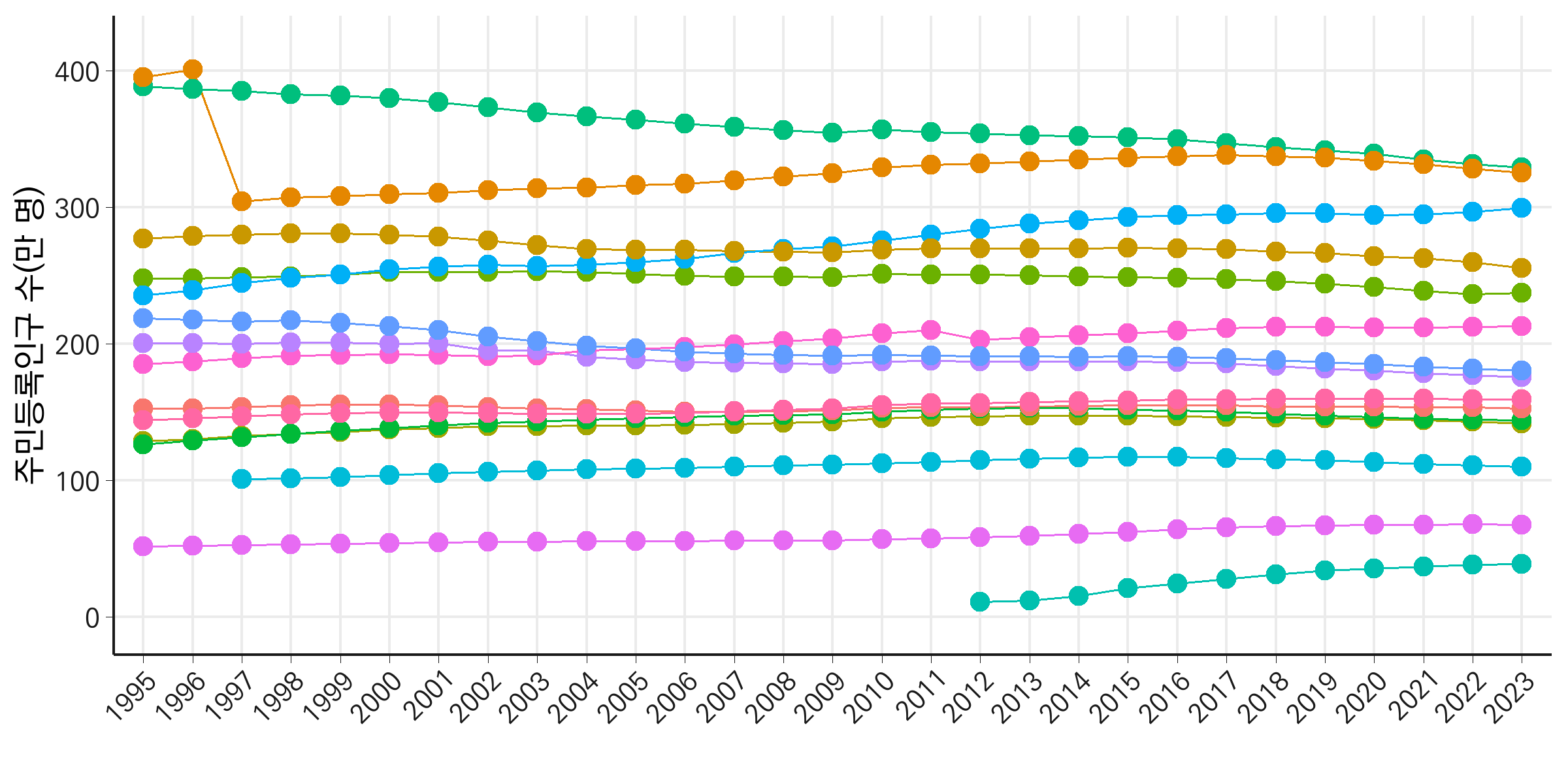
하지만 기본적으로 y축 값이 커 과학적 표기법(예: 1e+07)으로 표시되어 직관적으로 이해하기 어려운 문제가 있습니다. 이를 해결하기 위해, y축 단위를 ’만 명’으로 변환하여 보다 읽기 쉽게 조정합니다. 또한, 서울특별시와 경기도의 주민등록인구수가 다른 시도들에 비해 매우 높아 다른 시도의 데이터를 제대로 관찰하기 어려운 점을 감안하여, 서울특별시와 경기도를 제외하겠습니다.
서울특별시와 경기도를 제외한 다른 시도의 주민등록인구 변화를 선 그래프로 나타내기 위해 데이터를 필터링합니다. 또한, 그래프를 더욱 명확히 하기 위해 몇 가지 사항을 조정합니다. 먼저, 선 그래프에 범례를 표시하지 않도록 show.legend = FALSE 옵션을 사용합니다. 이는 시도의 개수가 많아 범례가 그래프의 가독성을 저해할 수 있기 때문입니다. 또한, y축 값을 ‘명’ 단위에서 ‘만 명’ 단위로 변환하여 보다 직관적으로 데이터를 해석할 수 있도록 조정합니다. x축 텍스트가 겹치는 문제는 45도 회전으로 해결해줍니다.
data %>%
filter(!시도 %in% c("서울특별시", "경기도")) %>%
ggplot(aes(x = 시점, y = 주민등록인구수 / 10000,
group = 시도, color = 시도)) +
geom_line(linewidth = 0.4,
show.legend = FALSE) +
geom_point(size = 3,
show.legend = FALSE) +
scale_x_discrete(name = "") +
scale_y_continuous(name = "주민등록인구 수(만 명)",
labels = comma_format(accuracy = 1),
expand = expansion(mult = 0.1)) +
theme_minimal(base_size = theme.size, base_family = "kopub") +
theme(
axis.line = element_line(linewidth = 0.5, color = "gray10"),
axis.ticks = element_line(linewidth = 0.1, color = "gray10"),
panel.grid.minor = element_blank(),
axis.text = element_text(color = "gray10"),
axis.text.x = element_text(angle = 45, vjust = 1, hjust = 1)
)
선 그래프 우측에 텍스트 표기하기
이번 단계에서는 선 그래프의 끝 지점에 각 선이 어떤 시도를 나타내는지 텍스트로 표기하여 그래프의 가독성을 높여보겠습니다. 텍스트가 촘촘히 겹치는 문제를 해결하기 위해 geom_text_repel 함수를 활용합니다. 이 함수는 텍스트가 겹치지 않도록 자동으로 위치를 조정하며, 시각적으로 깔끔한 그래프를 만들 수 있도록 돕습니다. 또한, 시도명을 축약형으로 표기하겠습니다.
- 텍스트 정렬:
hjust = 0으로 설정하여 텍스트가 좌측 정렬되도록 지정합니다. - 위치 조정:
nudge_x = 3을 사용하여 텍스트가 선의 끝 지점으로부터 일정 거리만큼 떨어지도록 설정합니다. - 텍스트 위치 조정 방향:
direction = "y"로 지정하여 텍스트가 위아래로 이동하며 겹치지 않도록 조정합니다. - 연결선 색상 조정: 연결선 색상을
segment.color = "gray80"으로 좀 더 흐린색으로 변경합니다.
sido_text <- data %>%
mutate(시도 = case_when(grepl("(특별시)|(광역시)|(자치시)|(특별자치도)$", 시도) ~ substr(시도, 1, 2),
시도 == "경기도" ~ "경기",
T ~ paste0(substr(시도, 1, 1), substr(시도, 3, 3))
)) %>%
filter(시점 == "2023",
!시도 %in% c("서울", "경기"))
data %>%
filter(!시도 %in% c("서울특별시", "경기도")) %>%
ggplot(aes(x = 시점, y = 주민등록인구수 / 10000,
group = 시도, color = 시도)) +
geom_line(linewidth = 0.4,
show.legend = FALSE) +
geom_point(size = 3,
show.legend = FALSE) +
geom_text_repel(data = sido_text,
aes(x = 시점, y = 주민등록인구수 / 10000, label = 시도),
color = "gray10",
hjust = 0,
nudge_x = 3,
direction = "y",
segment.color = "gray80",
family = "kopub",
size = text.size
) +
scale_x_discrete(name = "") +
scale_y_continuous(name = "주민등록인구 수(만 명)",
labels = comma_format(accuracy = 1),
expand = expansion(mult = 0.1)) +
theme_minimal(base_size = theme.size, base_family = "kopub") +
theme(
axis.line = element_line(linewidth = 0.5, color = "gray10"),
axis.ticks = element_line(linewidth = 0.1, color = "gray10"),
panel.grid.minor = element_blank(),
axis.text = element_text(color = "gray10"),
axis.text.x = element_text(angle = 45, vjust = 1, hjust = 1)
)
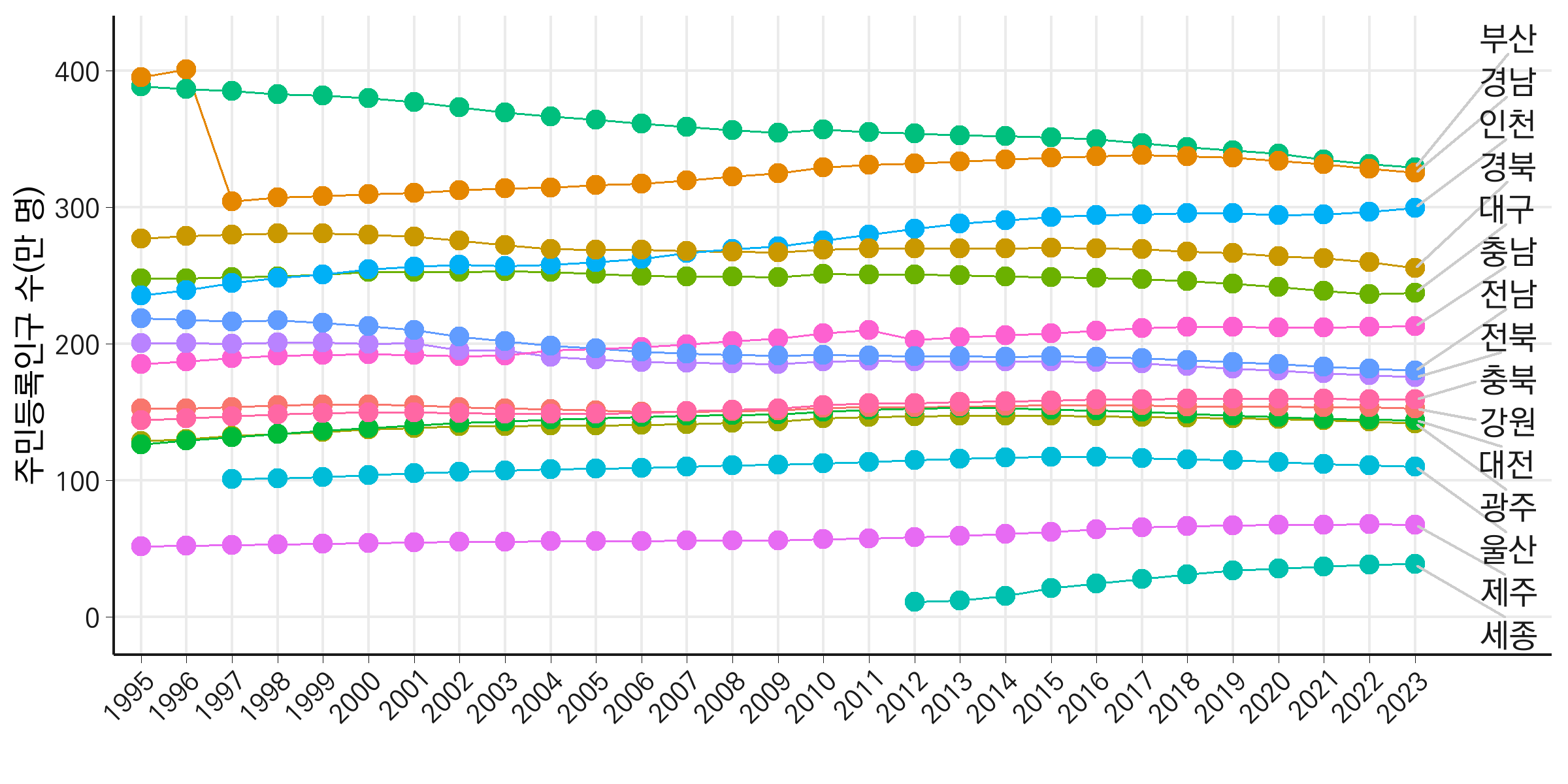
선 그래프에 텍스트를 추가하면 범례 없이도 각 선이 무엇을 나타내는지 쉽게 이해할 수 있어, 그래프를 훨씬 직관적으로 만들 수 있습니다. 특히 여러 그룹이 있는 복잡한 데이터에서도 텍스트를 활용하면 가독성을 높이고, 필요한 정보를 명확하게 전달할 수 있습니다. 이번에 사용한 geom_text_repel 함수는 텍스트가 겹치지 않도록 도와주어 깔끔한 차트를 만드는 데 도움을 줍니다. 데이터에 맞게 텍스트의 위치와 스타일을 조정하면서 활용해 보시면 더욱 효과적인 시각화를 만들 수 있을 거예요. 선 그래프와 텍스트를 결합해, 데이터를 더 이해하기 쉽게 표현해 보세요!