둘 이상의 속성 시각화
개요
여러 속성을 한눈에 시각화하는 방법을 알아보겠습니다. 이번 예제에서는 붓꽃 데이터셋(iris)을 활용해 다양한 속성을 시각화하는 팁을 소개합니다. 데이터에는 붓꽃의 종류별로 꽃받침 길이, 꽃받침 너비, 꽃잎 길이, 꽃잎 너비 등이 포함되어 있습니다.
먼저 데이터를 ggplot2로 그리기 쉽도록 pivot_longer를 사용해 데이터를 ‘longer’ 형태로 변환하겠습니다. 이 과정을 통해 여러 속성이 하나의 열로 묶이고, 각각의 값이 새로운 열에 담기게 됩니다.
# 패키지 로드
library(tidyverse)
# 데이터 불러오기
data <- iris %>%
rename(`꽃받침 길이` = Sepal.Length,
`꽃받침 너비` = Sepal.Width,
`꽃잎 길이` = Petal.Length,
`꽃잎 너비` = Petal.Width,
종류 = Species) %>%
group_by(종류) %>%
summarise_if(is.numeric, ~sum(.)/n())
# 데이터 변환
data2 <- data %>%
pivot_longer(cols = `꽃받침 길이`:`꽃잎 너비`,
names_to = "구분",
values_to = "값")
# 데이터 확인
head(data2)
## # A tibble: 6 × 3
## 종류 구분 값
## <fct> <chr> <dbl>
## 1 setosa 꽃받침 길이 5.01
## 2 setosa 꽃받침 너비 3.43
## 3 setosa 꽃잎 길이 1.46
## 4 setosa 꽃잎 너비 0.246
## 5 versicolor 꽃받침 길이 5.94
## 6 versicolor 꽃받침 너비 2.77
하나의 그래프로 그리기
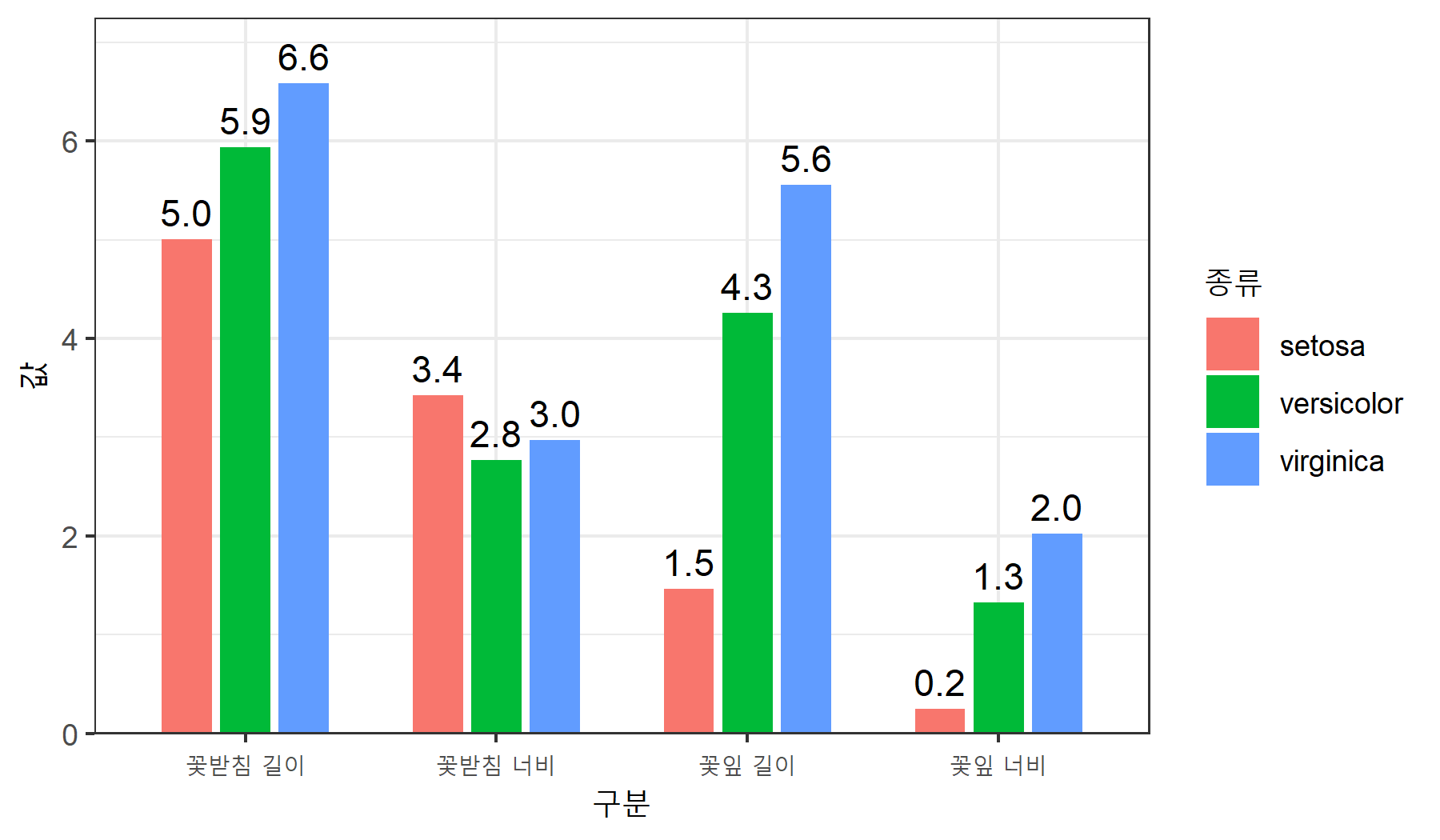
변환된 데이터를 활용해 모든 속성을 하나의 그래프로 시각화합니다.
- x축:
구분 - y축:
값 종류별로 그룹과 색상 구분
ggplot(data = data2,
aes(x = 구분, y = 값, group = 종류, fill = 종류)) +
geom_col(position=position_dodge(width = 0.7), width = 0.6) +
geom_text(aes(label=scales::comma(값, accuracy = .1)),
position=position_dodge(width = 0.7), vjust = -0.5) +
scale_y_continuous(expand = expansion(mult = c(0, 0.1))) +
theme_bw()
속성별 화면 분할하기
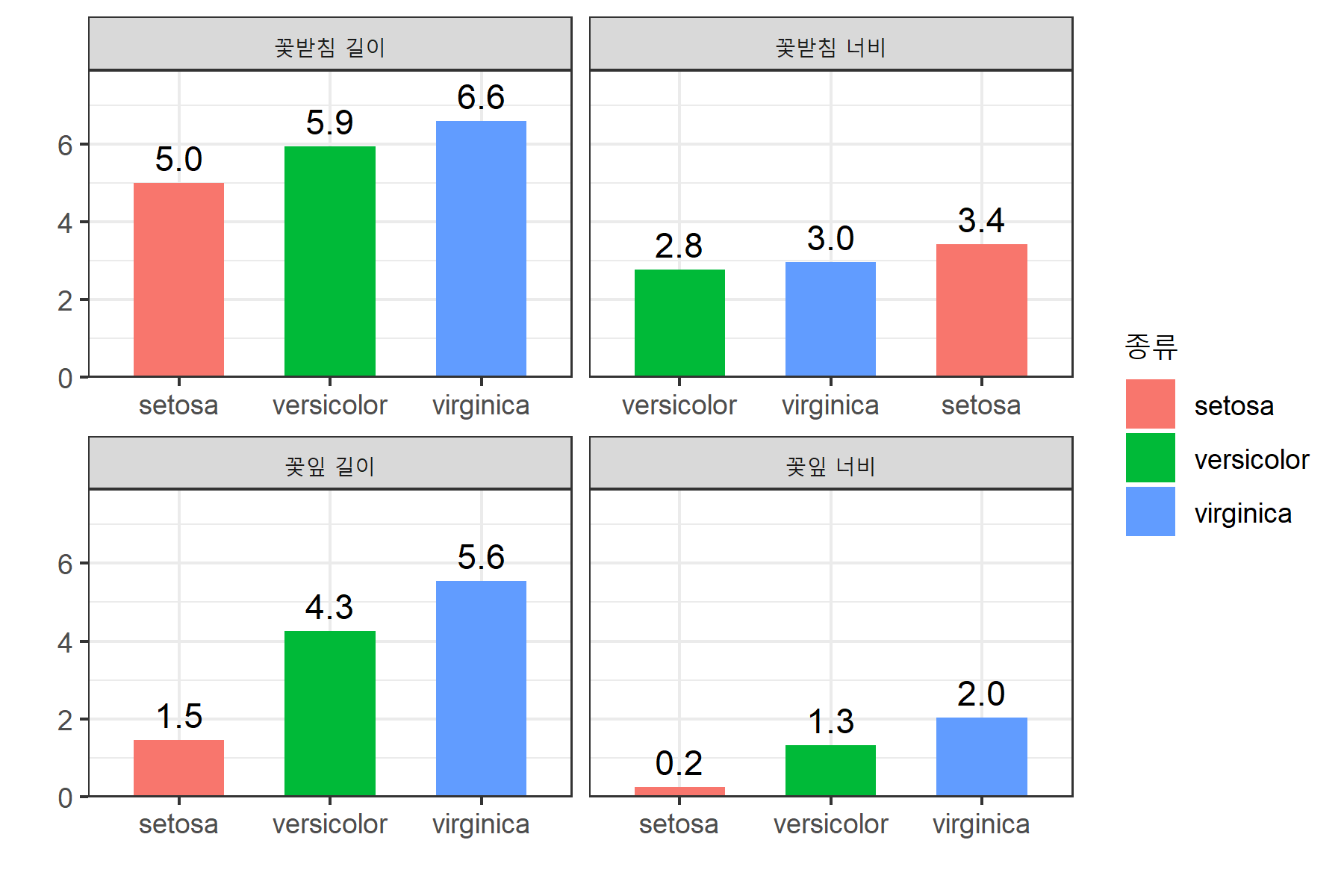
하나의 그래프에 모든 정보를 담는 대신, 각 속성을 별도의 화면으로 분할하여 시각화할 수도 있습니다. facet_wrap을 사용해 속성별로 화면을 나눕니다.
vars(구분): 속성(구분)을 기준으로 분할nrow=2: 2줄로 화면 배열
ggplot(data = data2, aes(x = 종류, y = 값, group = 종류, fill = 종류)) +
geom_col(width = 0.6) +
geom_text(aes(label = scales::comma(값, accuracy = .1)), vjust = -0.5) +
scale_x_discrete(name = "") +
scale_y_continuous(name = "",
expand = expansion(mult = c(0, 0.2))) +
facet_wrap(vars(구분), nrow = 2) +
theme_bw()

x축 순서 정렬하기
앞서 작성한 그래프에서 x축이 붓꽃 종류(setosa, versicolor, virginica)로 고정되어 있습니다. 속성별 값에 따라 막대를 오름차순으로 정렬하려면 tidytext 패키지의 reorder_within과 scale_x_reordered를 사용하면 됩니다.
# 패키지 로드
library(tidytext)
# 속성 내 값 기준 오름차순 정렬
ggplot(data = data2, aes(x = reorder_within(종류, 값, 구분), y = 값, group = 종류, fill = 종류)) +
geom_col(width = 0.6) +
geom_text(aes(label = scales::comma(값, accuracy = .1)), vjust = -0.5) +
scale_x_reordered(name = "") +
scale_y_continuous(name = "",
expand = expansion(mult = c(0, 0.2))) +
facet_wrap(vars(구분), nrow = 2, scales = "free_x") +
theme_bw()
이번에는 여러 속성을 효과적으로 보여주는 방식을 소개했습니다. 화면 분할, 정렬 등을 조합하여 복잡한 데이터를 직관적으로 표현할 수 있습니다. 위 코드를 참고하여 여러분 데이터에 맞는 시각화를 시도해 보세요!